I've written about this a few times now, to different audiences - a couple times to employers, and another to family. I thought it was time to consolidate it into one place. The original impetus was as a response to the urging of inclusion of "AI" tools both in the the workflow and the products I was working on. At the time, I was working for an avionics company, and already there were enough concerns with the LLM-based tools that it seemed like a bad idea to use them for our work on safety-critical products or in the products themselves. I further updated and refined it after I had left the avionics company and returned to the elevator company I had worked at previously. They also began talking about the use of "AI" tools in our development process.
My point of reference is primarily as a software developer, and technology enthusiast. However, I also love to read, and enjoy games and art … so it all comes in to play to some extent. However, I'll mostly be focusing on my corporate software developer role for this post. To that end, my perspective and arguments will largely be of a technical nature - keep in mind that this started as a document shared with company leadership, where I thought these arguments might get more traction. I think the moral, societal, and environmental impact of these tools are just as important, and the "AI" companies have likely committed irreparable harm in all these realms ... I could probably go on for just as long about each of those topics. However, I'll refrain from that for now, and just focus on the more technical arguments.
I'll get to my concerns about "AI" and the use of the tools incorporating it (I have several). But first, what is "AI" ... and why do I keep putting the term in quotes?
What is "AI"?
"AI", in its current usage, is a marketing term used to cover any Machine Learning (ML) or Large Language Model (LLM) based system to signify an advancement worthy of spending extra money on. Sometimes the advertising is directed at you and me (a developer, or a consumer), and other times it's directed at corporate purchasers - or management.
ML tools have their uses. I think of these as systems that train their models on narrow topics for a specific purpose. These have been used for many years with success; AlphaFold (Wikipedia, YouTube) is a good example of this.
One of the early goals for the project I'm working on was to use ML to train a model on an elevator's behavior patterns so we could detect anomalies in operation and send repair technicians to the site before a customer had even noticed an issue. This would have been a good use - while there are some commonalities, each installation also has its unique characteristics (traffic pattern, movement, etc.), and comparing current information to a "normal use case" model (that installation, trained on normal conditions) could help catch minor issues before they became major problems. I'm not sure this is still an end-goal though anymore - it's been years since I heard mention of it.
LLM tools also have their uses; analyzing large sets of natural language for patterns, for example. It is the nature of the model - statistical values placed on ordered symbols.
At the simplest level, a Generative AI tool (such as a chat-bot) is a statistical word guesser; it functions by statistically choosing a series of words/symbols based on the input as well as the generated output so far, with a target of satisfying the prompt. The input or basis for the statistical model is the large collection of training data that it has used - the occurrence of words and phrases appearing in the training data influences the generated output.
For a good explainer on how LLMs actually work, I recommend this post titled ... How LLMs Actually Work. It is a bit technical, but glosses over the deeper technical discussions and math, resulting in a good overview for most people.
There is no "Intelligence", artificial or otherwise - there is no understanding or reasoning. It is simply the numerical likelihood that one word or symbol has followed others before in a way that may approximate a response to an request.
Now, on to my specific thoughts that I mentioned at the start.
Quality and Correctness … Garbage In - Garbage Out
Since the output of an LLM tool is based on the likelihood of words appearing in a certain order (roughly fulfilling a request), at best the output is unlikely to be novel, being based solely on existing work. And at worst, it will be neither novel or correct, as the large source of training data is likely to have errors and bugs.
Garbage in, Garbage out: If you feed a system with unreliable data, the output will also be unreliable.
LLMs have been trained on vast troves of code scraped from repositories, help/Q-A systems (e.g., Stack Overflow), and other web pages across the internet. As anyone who has looked at other random source code out there can confirm, there is a wide range in the quality of code posted to the internet - from terrible to great (without discernment, both are of equal value).
At the scale that this scraping is being done, it is unlikely that any of this code is vetted for correctness or safety … that would require many humans spending countless hours evaluating and testing code - and that goes against the ethos of "AI" companies and their investors. So much for discernment.
Therefore, the generated output is also likely to contain errors – some obvious, and some more subtle. Below is a post by David Chisnall about is experience with some of the subtle errors produced during his testing of GitHub's Copilot system.
Using these tools to generate any code at all adds an additional task to the developer's workflow: code review from an unknown source.
While it's true that developers already do this (or should be doing this) for contributions from team members. This has the added components of being from a system that claims that it is correct, has a potentially unfamiliar style (a style which may be comprised of many input styles), and cannot truly evaluate or explain its logic or reasoning.
Cory Doctorow wrote an essay titled "Humans in the loop" must detect the hardest-to-spot errors, at superhuman speed:
Automation can augment a worker. We can call this a "centaur" – the worker offloads a repetitive task, or one that requires a high degree of vigilance, or (worst of all) both. They're a human head on a robot body (hence "centaur"). Think of the sensor/vision system in your car that beeps if you activate your turn-signal while a car is in your blind spot. You're in charge, but you're getting a second opinion from the robot.
Likewise, consider an AI tool that double-checks a radiologist's diagnosis of your chest X-ray and suggests a second look when its assessment doesn't match the radiologist's. Again, the human is in charge, but the robot is serving as a backstop and helpmeet, using its inexhaustible robotic vigilance to augment human skill.
That's centaurs. They're the good automation. Then there's the bad automation: the reverse-centaur, when the human is used to augment the robot.
…
An AI-assisted radiologist processes fewer chest X-rays every day, costing their employer more, on top of the cost of the AI. That's not what AI companies are selling. They're offering hospitals the power to create reverse centaurs: radiologist-assisted AIs. That's what "human in the loop" means.
…
Humans are good at a lot of things, but they're not good at eternal, perfect vigilance. Writing code is hard, but performing code-review (where you check someone else's code for errors) is much harder – and it gets even harder if the code you're reviewing is usually fine, because this requires that you maintain your vigilance for something that only occurs at rare and unpredictable intervals:
…
But for a coding shop to make the cost of an AI pencil out, the human in the loop needs to be able to process a lot of AI-generated code. Replacing a human with an AI doesn't produce any savings if you need to hire two more humans to take turns doing close reads of the AI's code.
The use of these tools changes the nature of the work we do - from creation to inspection. Since we risk the possibility of garbage out, significant time and energy must go into reviewing the generated output - shifting more of the task over toward code review. As noted earlier, this is a normal part of our current job - reviewing the code of others during pull requests and collaboration - we find errors there … and we also sometimes miss errors. However, adding additional review of plausible, but possibly subtly wrong code, is a burden I'm not interested in shouldering. At the very least, when I ask a question about the reasoning of code I'm reviewing, I expect the author to be able to walk me through the decision making process and logic.
Legal Concerns and Privacy
As these systems are trained on data scraped from the Internet (often with no authorization to do so), the resulting output could open up legal issues.
The company I work for has historically been sensitive to licensing. There is not a reliable way of ensuring that the generated code is not a copy of existing code, which may be protected by a license the company does not have or is not willing not use – the user cannot necessarily determine the source of the data. This has occurred, as noted in the book The AI Con:
We’ve also seen that these tools do a lot of whole-cloth copying of training data. In an early release of Copilot, open-source developer Armin Ronacher discovered that, given the prompt to code the “fast inverse square root” (a speedy approximation of a mathematical formula useful for graphics processing), Copilot regurgitated the exact computer code written by V. Petkov in the popular videogame Quake III Arena – down to the copyright and the swear-laden comments.
28 Armin Ronacher: Armin Ronacher (@mitsuhiko), “I don’t want to say anything but that’s not the right license Mr Copilot,” Twitter, July 2, 2021, https://twitter.com/mitsuhiko/status/1410886329924194309.
In this particular case, the file header provided licensing terms, and there were clues (specific comments) that this was someone else's code. However, it may not always be obvious and the use of this code could cause legal and financial issues for the company.
This type of issue was mentioned in David Chisnall's post, but there is also another side of the legal issue - that is revealing company information.
One must assume that any data fed into a prompt will be used by the LLM owner in future training and may end up as output - or in internet search results (ars Technica - ChatGPT users shocked to learn their chats were in Google search results).
Fast Company exposed the privacy issue on Wednesday, reporting that thousands of ChatGPT conversations were found in Google search results and likely only represented a sample of chats “visible to millions.” While the indexing did not include identifying information about the ChatGPT users, some of their chats did share personal details—like highly specific descriptions of interpersonal relationships with friends and family members—perhaps making it possible to identify them, Fast Company found.
Therefore, any existing company code, information, or secrets may be made available and discoverable outside the company or to the general public
I noted earlier that there is no intelligence in these tools. It is the numerical likelihood of one word or symbol following another.
What a person might perceive as learning (outputs getting better the more inputs that are provided) is the model consuming your inputs (whether personal information or you're company's internal code/data) and adding it to the training data that it draws on.
In the promoted use case, it would help refine the base model to provide more relevant and useful output. This could be text results that incorporate additional information you have provided, or code output that more closely matches expectations (better formatting, closer to solving a problem, etc.).
Maybe this extra data is kept isolated as personal model extensions. However, having observed the tech industry for decades, and seeing how the companies behind the tools have operated, I wouldn't trust that it would stay that way - either intentionally (i.e., the company deciding they can use or sell your data for other purposes, either changing the terms or just their actions) or not (e.g., data breaches and leaks).
Just this week, it surfaced that Microsoft changed the licensing terms for its Office for Mac 2019 product, making purchased software no longer able to function as sold. Additionally, they changed their "End of support page" with acknowledging the change, shown below (the updated page removes the text "will continue to function").
| Archived Page | Updated Page |
|---|---|
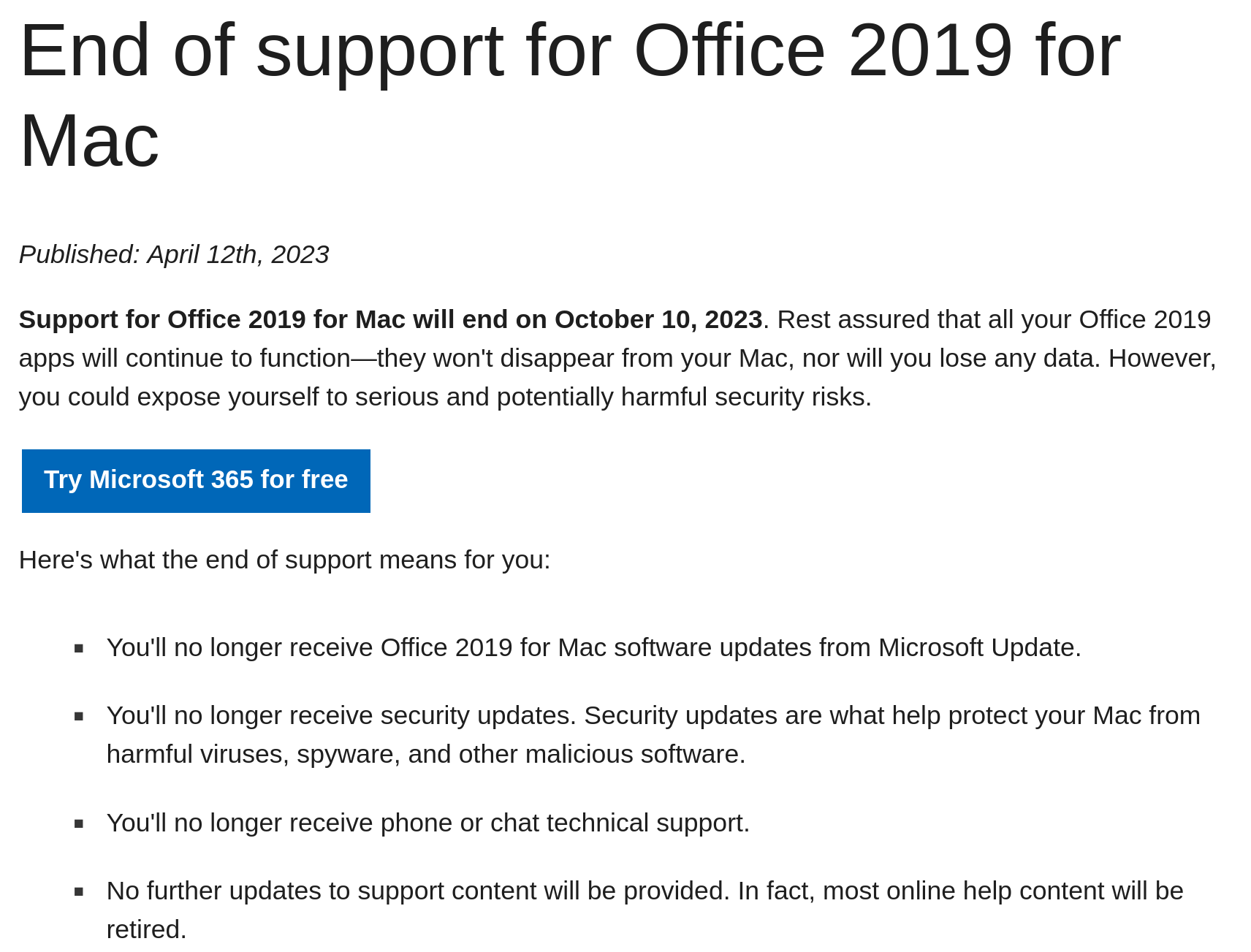 |
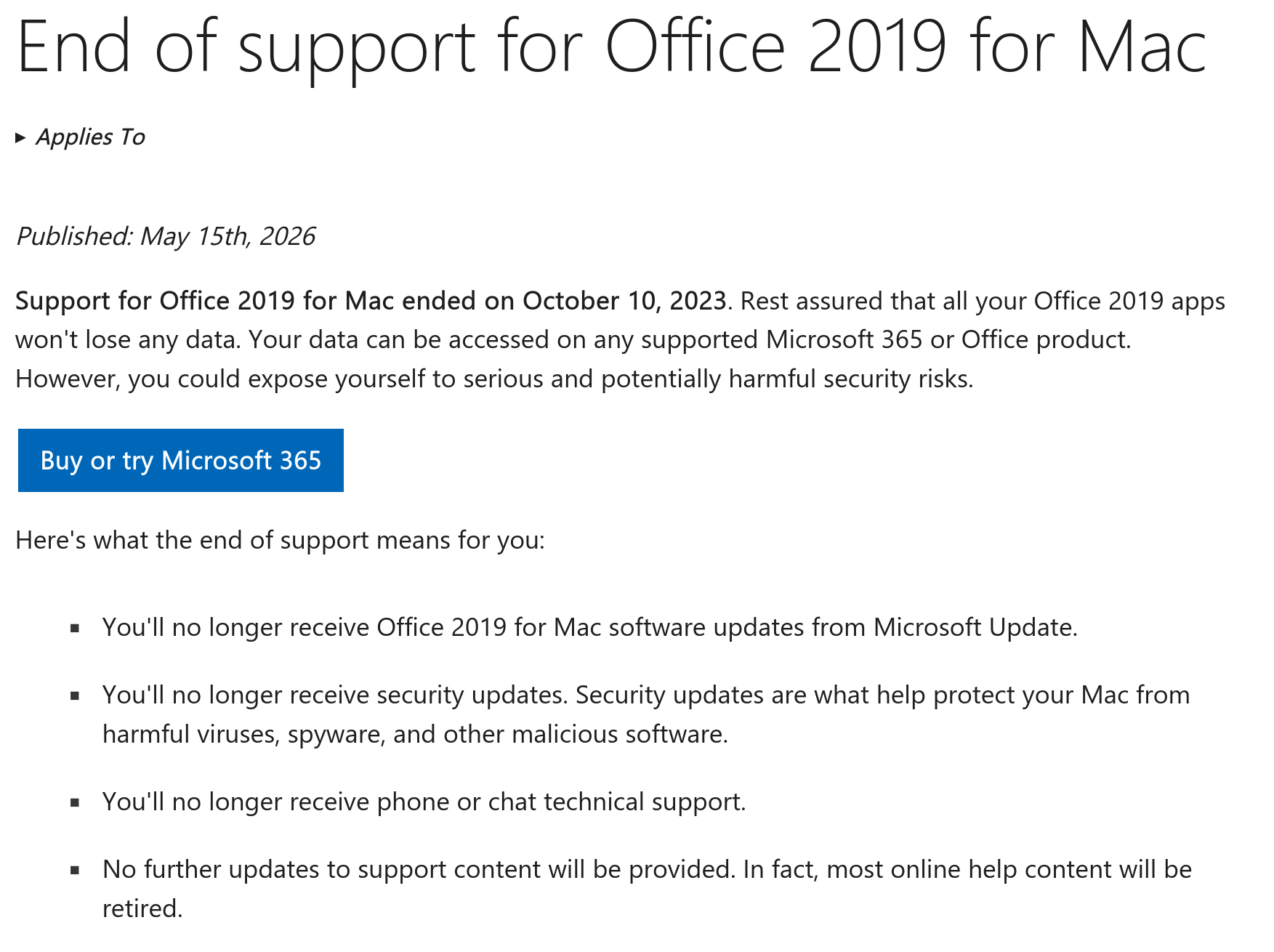 |
Louis Rossman covered this in a video this week:
So, I personally, don't trust that these "AI" companies will be bound by the terms that they set.
Skill & Knowledge
"AI" responses are designed to eliminate friction. Chat-bots offer sycophancy and generated code often looks right (sometimes is, sometimes isn't … it's a fun game). However, friction is where the rubber meets the road; that's what triggers exploration, experimentation, and learning that lasts beyond the current task.
I've spent countless hours exploring ways to solve a task, only to shelve it because it didn't work how I'd hoped or to discard it because it didn't work at all. On paper, this would look like failure. However, I don't consider this to be wasted time; it was time spent in the lab learning how new things work together - or don't work together. These things are now in my brain, so when a situation arises where that shelved work does fit, I've already got a head start on a solution.
I used to spend a lot of time with my grandfather. And sometimes (often enough that it stuck with me) we would go to the hardware store. He didn't always need anything at the time, but we would walk every aisle anyway. He was cataloging and refreshing his memory about what was available. He was creative and was an inventor, so these trips were exercises in inspiration. Maybe a current project could move forward if he happened to see just the right part. Maybe he'd get an idea for a future project. Or, maybe while he was working on a project in the future, he'd remember seeing a part from walking the aisles. It was an extension of his lab work.
Even beyond using "AI" to generate new code, it's been suggested as a tool to analyze code, to summarize the behavior or intention, and to locate sections of interest. While I agree that this could be useful, to a degree, to speed up analysis (assuming correctness, for the moment), the work of searching through code, trying to puzzle out what some legacy logic is doing, and identifying the parts of interest is all productive work (friction) that informs future changes. It is similar to walking the hardware store aisles looking at parts and tools to see what can be used now and remembering later what we saw that could be useful.
By removing the friction, "AI" tools deprive us of this productive work, and can effectively sabotage future projects by reducing or eliminating the problem solving skill and knowledge that it leads to.
Personal Motivation
This is a personal consideration, and may not apply to many other people. However, it is very important for me, and I suspect there are other people out there who probably do feel similarly, even if they can't name the feeling exactly.
I work to live, to have a roof over my head and to provide food, security, and comfort. This is a reality of this world.
To not feel completely miserable while working to stay alive, I have chosen a field where I get to solve puzzles. That is THE part of the job that is enjoyable - it's not the meetings, typing, etc. ... it's the puzzling out a solution to a problem.
Figuring out how a piece of software works - we've all heard the stories about children taking things apart and putting them back together again, I was one of those - making improvements ... these are the bits that motivate me to keep working.
Final Thoughts
I've been following and thinking about these topics for some time, and I've used some of them and seen the wild outputs given - not with code specifically, but natural language output in a flight-system voice-to-text demonstration that I was developing based on OpenAI's Whisper models; this is a language task where LLMs should thrive. Recorded voice - clearly audible and enunciated, would sometimes produce strange combinations of text output.
One interesting and easy test is to ask the tools questions you either know the answer to, or is in your field of expertise. How accurate are the outputs and how easy is it to verify the results? Are there issues? How confident do the results sound when there are issues? This is a good first step in using a tool you don't know - to help build trust.
In most cases, people are skipping these steps and are using these tools to answer questions they know nothing about. They then believe the answers - because they sound right, and the tools have been hyped as "intelligent".
LLM based tools can have their place, but they need to be used with caution and proper consideration. Carefully think about what information and detail is given in a prompt, and carefully think, check, and verify the outputs that are generated.
Resources
This will be a collection of authors, articles, or videos which I have found useful or interesting on the topic.
- Cory Doctorow (Pluralistic) - Cory touches on how technology interacts with and affects people.
- Better Offline (podcast) - Ed Zitron (Where's YourEd At) discusses AI and technology.
- 404 Media - Independent News Media focusing on technology and how it impacts our lives.
- The AI Con - Emily M. Bender's and Alex Hanna's book on AI, its background, and the hype surrounding it.
- Blood In The Machine - Brian Merchant's book covering the Industrial Revolution and the Luddites, the impact the new technologies had on their lives, their cause and struggles, and the parallels with AI and tech generally.
- Timnit Gebru - Former Google researcher, fired for not retracting her paper On the Dangers of Stochastic Parrots:
Can Language Models Be Too Big?- A recent retrospective of the Stochastic Parrot paper by Darren O'Connor
- DAIR (Distributed AI Research) Institute
- Mystery AI Hype 3000 Podcast